
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 대학원 급여
- 의료 ai 대학원 월급
- 딥러닝 실험 깃 버전관리
- 영화 api
- 파이썬 경사하강법
- 자바 프로젝트
- 정규화
- 인공지능 깃 버전관리
- 파이썬
- API
- 로스트아크
- 자바 영화 api
- C# 프로젝트
- 백준
- MLP
- 대학원 월급
- 인공지능
- 코딩테스트
- pandas
- DCP
- 디자인 패턴
- 딥러닝
- python
- 디자인패턴
- Dehaze
- 활성화 함수
- 통계학
- 자바
- 머신러닝
- 경사하강법
- Today
- Total
대학원 일기
기계 학습(Machine Learning) 본문
※본 포스팅에서는 기계학습을 이해하고, 종류에 대해 간략히 알아보는 것이므로 자세한 알고리즘에 대해서는 나오지 않습니다.
기계학습(Machine Learning)이란?
머신러닝이란 컴퓨터가 학습을 하는 것으로 학습은 경험을 통해 행동의 변화 또는 잠재력의 변화를 만드는 것이다. 즉, 컴퓨터에 데이터를 제공하여 학습시키고 새로운 지식을 얻게 하여 인공지능을 더욱 똑똑한 모델로 만드는 것이다. 머신러닝은 인공지능의 한 분야로 딥러닝과 함께 그림으로 표현하면 아래와 같다.

머신러닝(Machine learning)의 종류: 지도, 비지도, 강화학습
머신러닝에서는 학습하는 방법에 따라 분류하고 있다. 컴퓨터가 학습(learning)할 때 교재(data)가 있을 경우 지도 학습과 비지도 학습이라고 부르고 교재(data) 없이 환경으로부터 학습할 때 강화 학습이라고 한다.

지도 학습(Supervised learning)
지도 학습(Supervised learning)은 학습 교재인 데이터와 데이터를 설명하는 레이블을 데이터셋(Dataset)으로 하여 학습하는 경우이다. 이러한 지도 학습은 분류(Classification)하거나 회귀(Regression)를 하기 위해 사용한다.
회귀(Regression)
회귀(Regression)는 예측하고 싶은 값(종속 변수)이 수치(숫자, 연속적인 값)일 때 사용한다.
아래 표에서 온도에 따라 판매량이 변하는 것을 확인할 수 있다. 즉, 온도가 종속변수가 되고 판매량이 구해야하는 값이 된다. 여기서 판매량은 수치를 나타내므로 회귀(Regression)에 대한 예라고 할 수 있다.
| 날짜 | 요일 | 온도 | 판매량 |
| 2021.12.29 | 수 | 20 | 40 |
| 2021.12.30 | 목 | 21 | 42 |
| 2021.12.31 | 금 | 22 | 44 |
| 2021.1.1 | 토 | 23 | ??? |
회귀(Regression)의 종류는 선형 회귀(Linear regression), 로지스틱 회귀(Logistic regression), 단계별 회귀(Stepwise regression) 등이 있다.
- 선형 회귀: 선형 예측식을 찾는 방법. 오차(loss)는 MSE(Mean Squared Error)를 통해 구한다.
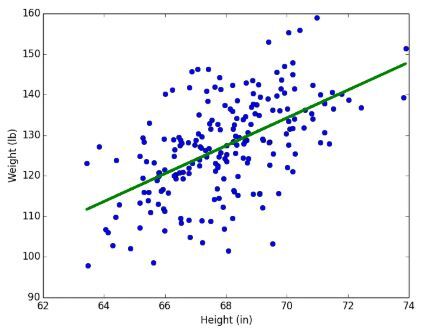
선형 회귀(Linear regression) - 로지스틱 회귀: 두 가지의 값 중 한 가지를 찾는 이진 예측을 할 때 사용한다.

로직스틱 회귀(Logistic regression) - 단계별 회귀: 고려해야할 입력 데이터들이 많을 때 점차적으로 항목을 고려해 나가다 일정한 항목 이상에서도 크게 정확도가 개선되지 않을 때 중단하고 그때까지 고려한 항목의 데이터만을 가지고 예측식을 찾는 방법이다.
분류(Classification)
분류(Classification)는 예측하고 싶은 종속 변수가 이름(단어, 이산적인 값)일 때 사용한다. 분류의 알고리즘은 레이블에 있는 데이터를 학습하여 새롭게 입력된 데이터가 어느 레이블에 속하는지를 찾는 것이다. 분류의 종류에는 kNN 모델, 서포트 벡터 머신(SVM: Support Vector Machine), 디시즌 트리(Decison Tree) 등이 있다.
- kNN(K-Nearest Neighbor) 모델: 입력된 학습 데이터를 미리 추출한 후 새로운 데이터로부터 거리가 가까운 K개의 다른 데이터의 레이블(속성)을 참고하여 K개의 데이터 중 가장 빈도 수가 높게 나온 데이터의 레이블로 분류한다.
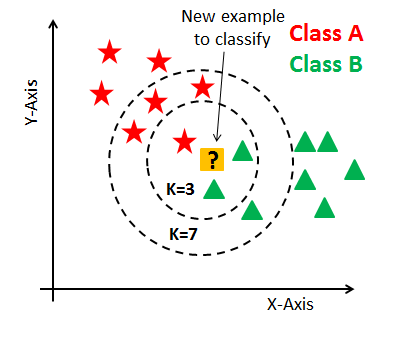
K=3일 때 Class A로 분류, K=7일 때 Class B로 분류 - 서포트 벡터 머신(SVM: Support Vector Machine): SVM은 이진선형분류(Binary Linear Classification) 모델로 2개의 그룹을 직선 또는 면과 같은 선형분류기(Linear Classifier)로 분류하는 모델이다. SVM의 알고리즘은 학습 데이터의 특성을 미리 추출한 후 d차원 공간에 각 데이터를 위치시킨 후 두 개의 개체 그룹을 가장 멀리 떨어뜨려서 분리하는 선형판별식을 찾는 것이다. 이 방법을 두 그룹 간의 마진을 최대화 한다고 표현하고, SVM의 목적이라고 볼 수 있다.
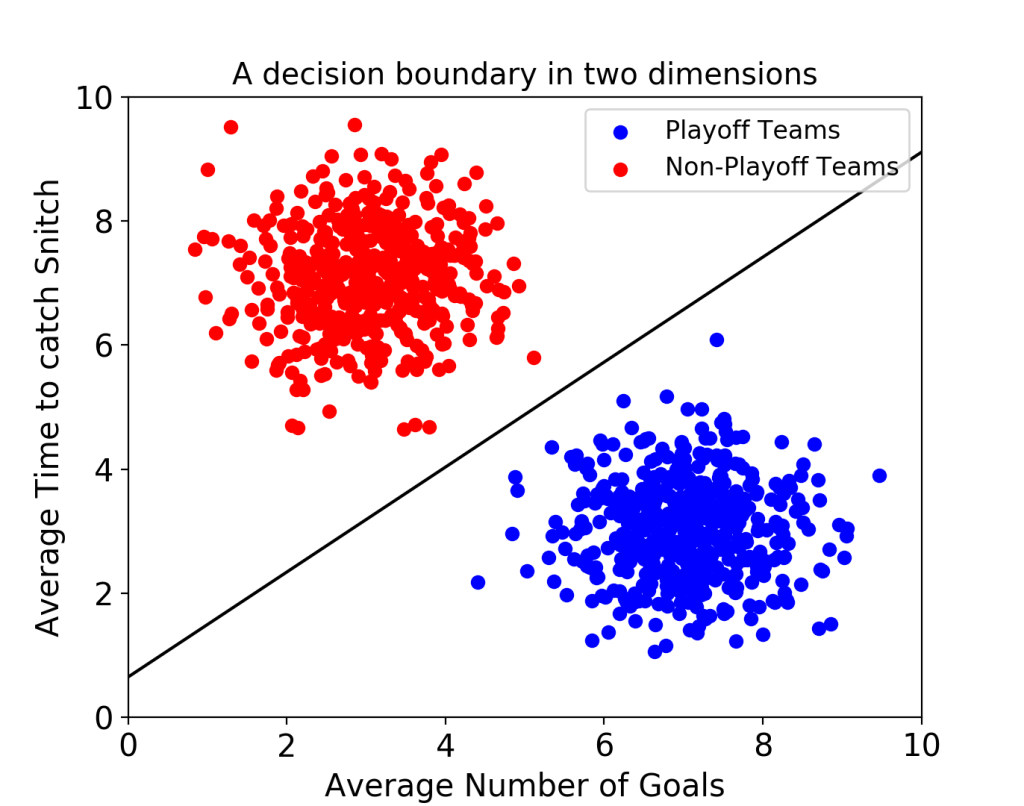
비지도 학습(Unsupervised learning)
비지도학습은 레이블 없이 학습 교재인 데이터만 가지고 학습하는 경우이다. 비지도학습의 목적은 입력받은 학습 데이터들이 가지고 있는 특징들을 추출하여 연관된 것을 찾고 그룹화하는 것이다. 비지도학습의 종류는 군집화(Clustering), 생성모델(Generative Model) 등이 있다.
군집화(Clustering)
군집 모델은 레이블 없이 입력받은 데이터의 특성을 분석하여 서로 유사한 특성을 가진 데이터끼리 그룹화하는 것이 군집 모델의 학습 목표이다. 군집 모델의 종류에는 k-means/k-mediods, DBSCAN, GMM, 계층적 군집화 등이 있다.
- k-means/k-mediods: k-평균 알고리즘은 주어진 데이터를 k개의 클러스터(그룹)로 묶는 알고리즘이다.

- DBSCAN(Density-based spatial clustering of applications with noise): 밀도 기반 클러스터링(DBSCAN)은 d차원 공간에 위치한 데이터들이 사용자가 정의한 밀도(density)를 유지한 채 이웃하고 있으면 같은 그룹으로 정하는 방법이다.
- GMM(Gaussian Mixture Model): 가우시안 혼합 모델은 소프트 클러스터링 방식으로 어떤 데이터가 어느 그룹에 더 높은 확률로 클러스터에 속하는지 모르는 것을 알고자 할 때 사용한다.
생성 모델(Generative Model)
생성모델은 주어진 학습 데이터를 학습하여 학습 데이터의 분포를 따르는 유사한 데이터를 생성하는 모델이다. 레이블이 있는 데이터로 학습하는 지도학습을 판별모델이라고 할 때, 판별모델은 객관식 문제라고 비유할 수 있고, 생성모델은 주관식으로 비유할 수 있다. 즉, 생성모델은 주어진 데이터를 기반으로 이를 가장 잘 표현할 수 있는 결과물을 생성한다.

최근 인공지능 분야에서는 비지도학습인 생성모델에 대한 연구가 인기있는 추세이고, 다양한 방법들을 시도하고 있다. 인공신경망 기술을 기반으로 발표된 모델 중으로는 GAN(Generative Adversarial Network)과 VAE(Variational Auto-Encoder)가 유명하다.
강화 학습(Reinforcement learning)
강화학습은 지도 및 비지도학습과는 다르게 정적 데이터에 의존하는 것이 아니라 역동적인 환경에서도 동작하여 수집했던 경험으로부터 학습을 하는 것이다. 강화학습은 에이전트가 취한 행동에 따라 환경이 각각 다른 상태를 보여주는데 이때 사람이 개입하여 각 상태에 대한 보상과 벌칙의 피드백을 준다. 강화학습 모델은 환경으로부터 피드백을 받고, 그 과정 속에서 모델 스스로가 시행착오를 받으면서 학습하게 되는 것이다. 즉, 강화학습의 목표는 주어진 환경에서 보상을 최대한 많이 받을 수 있도록 학습하는 것 이다. 강화학습의 학습 모델 중 유명한 응용 사례로 알파고(AlphaGo)가 있다.
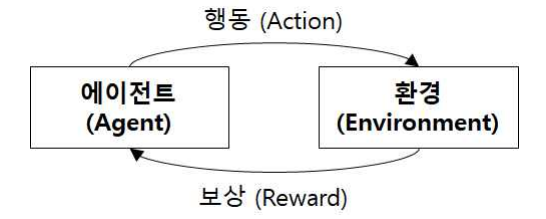
'AI > 인공지능 기초' 카테고리의 다른 글
| 행렬(Matrix) (0) | 2022.01.26 |
|---|---|
| 벡터(Vector) (0) | 2022.01.26 |
| Numerical Python - Numpy (0) | 2022.01.25 |
| [DL] Deep Learning, Historical Review (0) | 2022.01.07 |
| 인공지능(Artificial Intelligence)의 분류 (0) | 2021.12.30 |


