
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 활성화 함수
- Dehaze
- 영화 api
- 통계학
- 자바 프로젝트
- 자바
- 경사하강법
- 파이썬 경사하강법
- 의료 ai 대학원 월급
- 딥러닝
- pandas
- API
- 인공지능
- python
- 대학원 급여
- 파이썬
- C# 프로젝트
- 디자인패턴
- 디자인 패턴
- 대학원 월급
- 로스트아크
- MLP
- DCP
- 코딩테스트
- 정규화
- 자바 영화 api
- 딥러닝 실험 깃 버전관리
- 인공지능 깃 버전관리
- 백준
- 머신러닝
- Today
- Total
대학원 일기
pandas II 본문
Pandas II
- Groupby
- Hierarchical index
- aggregation
- transformation
- pivot table
- merge & concat
- join
- DB persistence
Groupby
- SQL 쿼리문의 명령어와 같음
- 기존 데이터에서 Key 값을 기준으로 split을 해주고, 어떠한 함수(sum)를 적용해주고 결과값을 결합(combine)한다.
- 과정을 거쳐 연산함: split → apply → combine

df = pd.DataFrame(ipl_data)
groupby_1 = df.groupby("Team")["Points"].sum()
groupby_2 = df.groupby(["Team", "Year"])["Points"].sum()- 한 개 이상의 column으로도 묶을 수 있다.

Hierarchical index
- Groupby 명령의 결과물도 결국은 dataframe
- 두 개의 column으로 groupby를 할 경우, index가 두개 생성
h_index = df.groupby(["Team", "Year"])["Points"].sum()
A = h_index.index
B = h_index["Devils":"Kings"]
Hierarchical index - unstack()
- Group으로 묶여진 데이터를 matrix 형태로 전환한다.
h_index.unstack()
Hierarchical index - swaplevel
- Index level을 변경할 수 있다.
h_index.swaplevel()
Hierarchical index - operations
- Index level을 기준으로 기본 연산 수행 가능하다.

Groupby II
Groupby – gropued
- Groupby에 의해 Split된 상태를 추출 가능함
- 특정 key값을 가진 그룹의 정보만 추출 가능

- 추출된 group 정보에는 세 가지 유형의 apply가 가능함
- Aggregation: 요약된 통계정보를 추출해 줌
- Transformation: 해당 정보를 변환해줌
- Filtration: 특정 정보를 제거 하여 보여주는 필터링 기능
Aggregation

Transofrmation
- Aggregation과 달리 key값 별로 요약된 정보가 아님
- 개별 데이터의 변환을 지원함

filter
- 특정 조건으로 데이터를 검색할 때 사용
- filter안에는 boolean 조건이 존재해야함
- len(x)는 grouped된 dataframe 개수

Merge & Concat
- SQL에서 많이 사용하는 Merge와 같은 기능
- 두 개의 데이터를 하나로 합침
df_a = pd.DataFrame(raw_data, columns = ['subject_id', 'test_score'])
df_b = pd.DataFrame(raw_data, columns = ['subject_id', 'first_name', 'last_name'])- df_a에는 subject_id와 test_score가 있고, df_b에는 subject_id와 first_name, last_name이 있다.
- subject_id 기준(on)으로 merge

- 두 dataframe이 column이름이 다를 때

Join method

how 를 사용하면 join하게 된다.
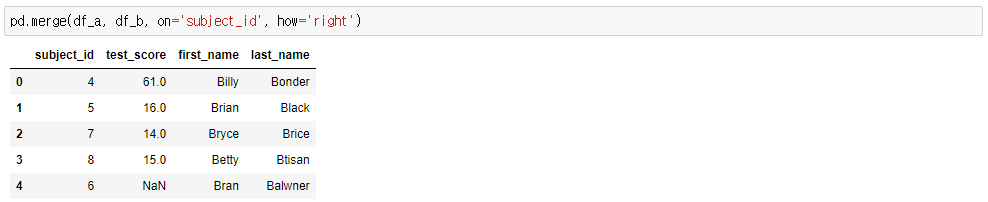
- df_a을 기준으로 db_b를 join함. LEFT JOIN(df_a 집합)

- df_b을 기준으로 db_a를 join함. RIGHT JOIN(df_b 집합)
- df_a와 df_b가 모두 가지면서 겹치는 subject_id를 출력. INNER JOIN(교집합이라고 생각)

- df_a와 df_b에 있는 모든 것을 출력. FULL JOIN(합집합이라고 생각)

index based join
- index 값을 기준으로 JOIN 함

DB Persistence
Load database
import sqlite3 #pymysql <- 설치
conn = sqlite3.connect("./data/flights.db")
cur = conn.cursor()
cur.execute("select * from airlines limit 5;")
results = cur.fetchall()
Data loading using pandas from DB
df_airplines = pd.read_sql_query("select * from airlines;", conn)
'AI > 인공지능 기초' 카테고리의 다른 글
| Machine Learning & Pytorch(Tensor Manipulation) (0) | 2022.02.22 |
|---|---|
| 파이썬 시각화툴(Matplotlib) (0) | 2022.02.14 |
| 선형(Linear) 데이터와 비선형(Non-linear) 데이터의 차이 (0) | 2022.02.03 |
| 딥러닝(Deep learning) 학습 방법 (1) | 2022.02.01 |
| pandas(1) (0) | 2022.01.31 |



