
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |
- 자바 프로젝트
- 정규화
- 디자인 패턴
- C# 프로젝트
- 활성화 함수
- 디자인패턴
- 경사하강법
- 대학원 월급
- pandas
- 코딩테스트
- API
- 대학원 급여
- 인공지능
- 영화 api
- 로스트아크
- 통계학
- 머신러닝
- 인공지능 깃 버전관리
- Dehaze
- MLP
- 파이썬 경사하강법
- 자바 영화 api
- 자바
- 파이썬
- python
- 딥러닝
- DCP
- 백준
- 딥러닝 실험 깃 버전관리
- 의료 ai 대학원 월급
- Today
- Total
대학원 일기
딥러닝 모델 학습 본문
4. 딥러닝 모델 학습
4-2 손실함수(Loss function)
-
학습이 진행되면서 해당 과정이 얼마나 잘 되고 있는지 나타내는 지표
-
모델이 훈련되는 동안 최소화될 값으로 주어진 문제에 대한 성공 지표
-
손실 함수에 따른 결과를 통해 파라미터를 조정하며 학습이 진행
-
손실함수는 최적화 이론에서 최소화하고자 하는 함수로 미분 가능 함수를 사용
-
케라스에서 제공되는 주요 손실함수
-
sparse_categorical_crossentropy
-
클래스가 배타적인 방식으로 구분
-
(0,1,2,3, ... ,9)
-
-
categorical_cross_entropy
-
클래스가 원핫 인코딩 방식으로 되어 있을 때 사용
-
-
binary_crossentropy
-
이진 분류를 수행할 때 사용
-
-
-
MAE
-
오차가 커져도 소실함수가 일정하게 증가
-
이상치에 강건한 특성
-
회귀에 많이 사용하는 손실함수
-
-
MSE
-
오차가 커질수록 손실함수가 빠르게 증가하는 특성
-
정답과 예측한 값의 차이가 클수록 더 많은 페널티를 부여하는 형태로 동작
-
회귀에 사용되는 손실함수
-
-
원핫인코딩
-
범주형 변수를 표현할 때 사용
-
가변수라고도 함
-
정답인 레이블만 1이고 나머지는 0으로 처리하는 형태
-
-
교차 엔트로피 오차
-
이진 분류 또는 다중 클래스 분류에 주로 사용
-
오차는 소프트맥스 결과와 원핫인코딩 사이의 출력 간 거리르 비교
-
정답을 맞추면 오차가 0, 틀리면 그 차이가클수록 오차가 무한히 커지게 됨
-
4-3 옵티마이저
-
손실함수를 기반으로 모델이 어떻게 업데이트되어야 하는지 결정
-
케라스에서 여러 옵티마이저를 제공하고, 사용자가 특정 종류의 확률적 경사 하강법 지정 가능
-
keras.optimizer.SGD() : 기본적인 확률적 경사 하강법
-
keras.optimizer.Adam() : 자주 사용되는 옵티마이저
-
-
보통 옵티마이저의 튜닝을 위해 따로 객체를 생성하여 컴파일시에 포함
-
경사하강법
-
미분과 기울기로 동작하며, 스칼라를 벡터로 미분
-
변화가 있는 지점에서는 미분값이 존재하고, 변화가 없는 지점은 미분값이 0이 되며, 미분값이 클수록 변화량이 큼
-
경사하강법의 과정은 한 스텝마다의 미분값에 따라 이동하는 방향을 결정, f(x)의 값이 변하지 않을때까지 반복
-
기울기가 0이지만 극값이 되지 않는 안장점(saddle point)가 존재
-
경사하강법은 안장점에서 벗어나지 못하는 문제가 있음
-
-
학습률
-
모델을 학습하기 위해서는 적절한 학습률을 지정해야 최저점에 잘 도달할 수 있음
-
학습률이 너무 크면 발산하고, 너무 작으면 학습이 오래 걸리거나 최저점에 도달하지 못하는 문제가 있음
-
-
지표(maetrics)
-
딥러닝 학습 시 필요한 다양한 지표들을 지정 가능
-
일반적응로 mae 나 accuracy를 사용
-
accuracy같은 경우 줄여서 acc라고도 사용이 가능
-
keras에서 사용되는 지표 종류: http://keras.io/ko/metrics/
-
4-4 딥러닝 모델 학습

-
먼저 데이터셋을 입력 X와 실제 정답(레이블)인 Y로 구분합니다.
-
입력 데이터는 연속된 레이어로 구성된 네트워크(모델)를 통해 결과로 예측 Y′을 출력합니다.
-
손실 함수는 모델이 예측한 Y′과 실제 정답인 Y와 비교하여 얼마나 차이가 나는지 측정하는 손실 값을 계산합니다.
-
옵티마이저는 손실 값을 사용하여 모델의 가중치를 업데이트하는 과정을 수행합니다.
-
모델이 새롭게 예측한 Y′과 실제 정답인 Y의 차이를 측정하는 손실 값을 계산하는 과정을 반복합니다.
-
계산한 손실값을 최소화하도록 옵티마이저가 동작하는 것이 딥러닝 모델 학습입니다.
데이터 생성
선형회귀(Linear Regression)를 위한 딥러닝 모델
데이터셋을 make_regression 함수를 이용하여 입력 X와 정답 y로 샘플 갯수(n_samples) 200개, 특징 갯수(n_featrues) 1개에 바이어스(bias)는 5.0, 노이즈(noise)는 5.0으로 지정하고, random_state는 123으로 하여 랜덤 시드를 지정해줍니다.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_regression
X, y = make_regression(n_samples=200, n_features=1,
bias=5.0, noise=5.0, random_state=123)
y = np.expand_dims(y, axis=1)
plt.scatter(X, y)
plt.show()from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(X, y,
test_size=0.2,
shuffle=True,
random_state=123)
print(x_train.shape, y_train.shape)
print(x_test.shape, y_test.shape)
모델 생성
먼저 딥러닝을 사용하는데 필요한 라이브러리인 Tensorflow와 keras를 임포트합니다. 케라스(Keras)의 모델, 레이어, 옵티마이저, 유틸을 사용할 수 있도록 models, layers, optimizer, utils도 임포트합니다.
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import models, layers, optimizers, utilsmodel = keras.Sequential()
model.add(layers.Dense(1, activation='linear', input_shape=(1,)))
model.summary()utils.plot_model(model)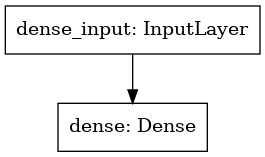
모델학습
딥러닝 모델의 학습 진행 방식을 결정하는 옵티마이저(optimizer)로 SGD(Stochastic Gradient Descent) 를 사용합니다. compile() 함수를 통해서 손실 함수(loss function), 옵티마이저(optimizer), 지표(metrics)를 지정합니다.
모델의 학습에 필요한 손실 함수로 mse를 지정하여 Mean Square Error를 사용하고, 옵티마이저는 정의했던 SGD를 사용합니다. 지표로는 mae와 mse를 사용하는데 여기서 MAE는 Mean Absolute Error를 의미합니다.
이제 모델 학습을 진행하기위해 fit() 함수를 호출합니다. 학습을 위해 x_train과 y_train를 지정하고, 학습 반복 횟수인 epochs를 40으로 지정합니다.
optimizer = optimizers.SGD()
model.compile(loss='mse', optimizer=optimizer, metrics=['mae', 'mse'])
history = model.fit(x_train, y_train, epochs=40)plt.plot(history.history['mae'])
plt.plot(history.history['mse'])
plt.xlabel('Epoch')
plt.legend(['mae', 'mse'])
plt.show();
모델 평가
이제 모델의 평가를 위해 evaluate() 함수를 이용하여 데이터셋인 x_test, y_test에 대해서 지표인 mae와 mse를 확인합니다.
model.evaluate(x_test, y_test)모델 예측
학습된 모델을 통해 입력 데이터 X에 대한 예측값을 predict()를 통해 결과로 받아옵니다. 실제 데이터의 결과값 y와 모델의 예측 결과인 result를 살펴봅니다.
result = model.predict(X)
plt.scatter(X, y)
plt.plot(X, result, 'r')
plt.show()model.layers
'''
[<keras.layers.core.Dense at 0x7f887a5179a0>]
'''layer = model.layers[0]
print(layer.name)
layer = model.get_layer('dense')
print(layer.name)
'''
dense
dense
'''weights, biases = layer.get_weights()
print(weights)
print(biases)
'''
[[22.915604]]
[4.183264]
'''plt.scatter(X, y)
plt.plot(X, np.array(weights * X + biases), 'r')
plt.show()
'AI > 인공지능 기초' 카테고리의 다른 글
| 케라스 창시자에게 배우는 딥러닝 2장 (1) | 2023.12.06 |
|---|---|
| 모델 저장과 콜백 (1) | 2023.12.06 |
| 딥러닝 구조와 모델 (0) | 2023.12.06 |
| 텐서 (Tensor) (0) | 2023.12.06 |
| 인공신경망과 딥러닝 (0) | 2023.12.04 |



