
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 자바 영화 api
- 대학원 월급
- 활성화 함수
- MLP
- 영화 api
- 디자인패턴
- 자바 프로젝트
- 대학원 급여
- 파이썬 경사하강법
- 의료 ai 대학원 월급
- C# 프로젝트
- 딥러닝
- 파이썬
- API
- 통계학
- 코딩테스트
- 백준
- DCP
- 경사하강법
- 딥러닝 실험 깃 버전관리
- 인공지능
- 자바
- pandas
- Dehaze
- 로스트아크
- 디자인 패턴
- 머신러닝
- 인공지능 깃 버전관리
- python
- 정규화
- Today
- Total
대학원 일기
Embedding, Recurrent Layer 본문
희소 표현(Sparse Representation)
대부분의 값이 0으로 이루어진 벡터 또는 행렬을 의미
벡터의 특정 차원에 단어 혹은 의미를 직접 매핑하는 방식
ex) 사과: [ 0, 0 ] , 바나나: [ 1, 1 ] , 배: [ 0, 1 ]
첫 번째 요소는 모양(0:둥글다, 1:길쭉하다), 두 번째 요소는 색상(0:빨강, 1:노랑)
분포 가설(distribution hypothesis)
유사한 맥락에서 나타나는 단어는 그 의미도 비슷하다
분산 표현(Distributed Representation)
유사한 맥락에 나타난 단어들끼리는 두 단어 벡터 사이의 거리를 가깝게 하고, 그렇지 않은 단어들끼리는 멀어지도록 조금씩 조정해 주는 방식으로 얻어지는 단어 벡터, 벡터의 특정 차원이 특정 의미를 담고 있는 것이 아니라 의미가 벡터의 여러 차원에 분산되어 있다고 여김.
Embedding 레이어
-
단어의 분산 표현을 구현하기 위한 레이어.
-
컴퓨터용 단어사전(Weight): n x k 형태의 분산 표현 사전(n: 단어의 개수, k: 차원의 개수)
-
입력으로 들어온 단어를 분산 표현으로 연결해 주는 역할을 하는데 그것이 Weight에서 특정 행을 읽어오는 것과 같아 이 레이어를 룩업 테이블(Lookup Table)이라고도 함
원-핫 인코딩(one-hot encoding)
N개의 단어를 N개의 차원으로 표현하는 방법. 단어가 포함되는 자리에는 1을 넣고 나머지는 0으로 채워줌.
단어 하나에 인덱스 정수를 할당한다는 점에서 “단어 주머니(bag of words, BOW)”라고 부르기도 함.
나름 좋은 성능을 내지만 가장 큰 단점은 단어의 의미 또는 개념 차이를 전혀 담지 못함.
또한 단어수 만큼 차원수를 갖게되어 계산 복잡성이 기하급수적으로 늘어나는 “차원의 저주” 문제도 가짐
one_hot = tf.one_hot(input, vocab_size) # input: index vector [2, 3, 3,...]sembedding layer
embedding_layer = tf.keras.layers.Embedding(input_dim=64, output_dim=100) # input_dim: vocab_size, output_dim: 차원수신경망을 사용하지 않는 훈련 방법
-
ELMo
-
Word2Vec
-
Glove
-
FastText
RNN
이전 정보를 반영하기 위한 방법
일반적인 neural network: input → hidden → output
-
prev_input을 넣어주기: (input + prev_input) → hidden → output # 바로 직전 input만을 기억
-
prev_hidden을 넣어주기: (input + prev_hidden) → hidden → output # 전부다 기억 가능, RNN에서 사용
공식
$h_t = f_w(h_{t-1} + X_t) = tanh(W_{hh} h_{t-1} + W_{xh} X_t)$
$y_t = W_{hy} h_t$
X: input, h: hidden_state, y: output, 모든 타임스텝에서 동일한
$W_{hh}, W_{xh}, W_{hy}$ 사용
타임스텝마다 들어가는 데이터만 바뀌는 것
다양한 형태
-
Many to many
-
각 timestep별 loss를 구해서 합함. supervised learning
-
전체 loss를 줄이는 방법으로 학습 (SGD 사용)
-
-
Many to one : 다이어트 여부 판단
-
One to Many: 그림 해석
-
Many to one(인풋시퀀스를 인코딩) + one to many(인코딩 벡터를 이용하여 아웃풋 시퀀스를 만듬) : 번역 모델
어떤 문장이 긍정인지 부정인지 나누기 위해서라면 문장을 모두 읽은 후, 최종 Step의 Output만 확인해도 판단이 가능 문장을 생성하는 경우라면 이전 단어를 입력으로 받아 생성된 모든 다음 단어, 즉 모든 Step에 대한 Output이 필요 tf.keras.layers.SimpleRNN 레이어의 return_sequences 인자를 조절함으로써 조절 가능
기울기 소실 (vanishing gradient)
RNN의 고질적인 문제점, 입력의 앞부분이 뒤로 갈수록 옅어져 손실이 발생합니다.
코드
# 문장 인덱스 벡터 만들기 ex) [2,3,3,...]
sentence_tensor = tf.constant([[dic[word] for word in sentence.split()]])
# embedding layer
embedding_layer = tf.keras.layers.Embedding(input_dim=len(dic), output_dim=100)
emb_out = embedding_layer(sentence_tensor)
# sequence 전체 반환하는 layer
rnn_seq_layer = tf.keras.layers.SimpleRNN(units=64, return_sequences=True, use_bias=False)
rnn_seq_out = rnn_seq_layer(emb_out)
# W_xh(100 * 64), W_hh(64 * 64) 출력
print(rnn_seq_layer.weights[0].shape, rnn_seq_layer.weights[1].shape)
# 마지막만 반환하는 layer
rnn_fin_layer = tf.keras.layers.SimpleRNN(units=64, use_bias=False)
rnn_fin_out = rnn_fin_layer(emb_out)
# W_xh(100 * 64), W_hh(64 * 64) 출력
print(rnn_fin_layer.weights[0].shape, rnn_fin_layer.weights[1].shape)LSTM (Long Short Term Memory)
RNN은 음성 인식, 언어 모델링, 번역, 이미지 주석 생성 등의 다양한 분야에서 의미있는 성능을 보여줬으나 간단한 RNN의 구조만으로는 한계가 있었습니다. 바로 장기 의존성(Long-Term Dependency) 을 잘 다루지 못하는 문제인데요. 입력데이터가 길어질 수록 데이터 앞쪽의 정보가 뒤쪽까지 전달이 잘 안되는 현상입니다. 이는 RNN의 hidden layer를 학습하는 과정에서 기울기 소실 문제가 발생하기 때문에 발생합니다.
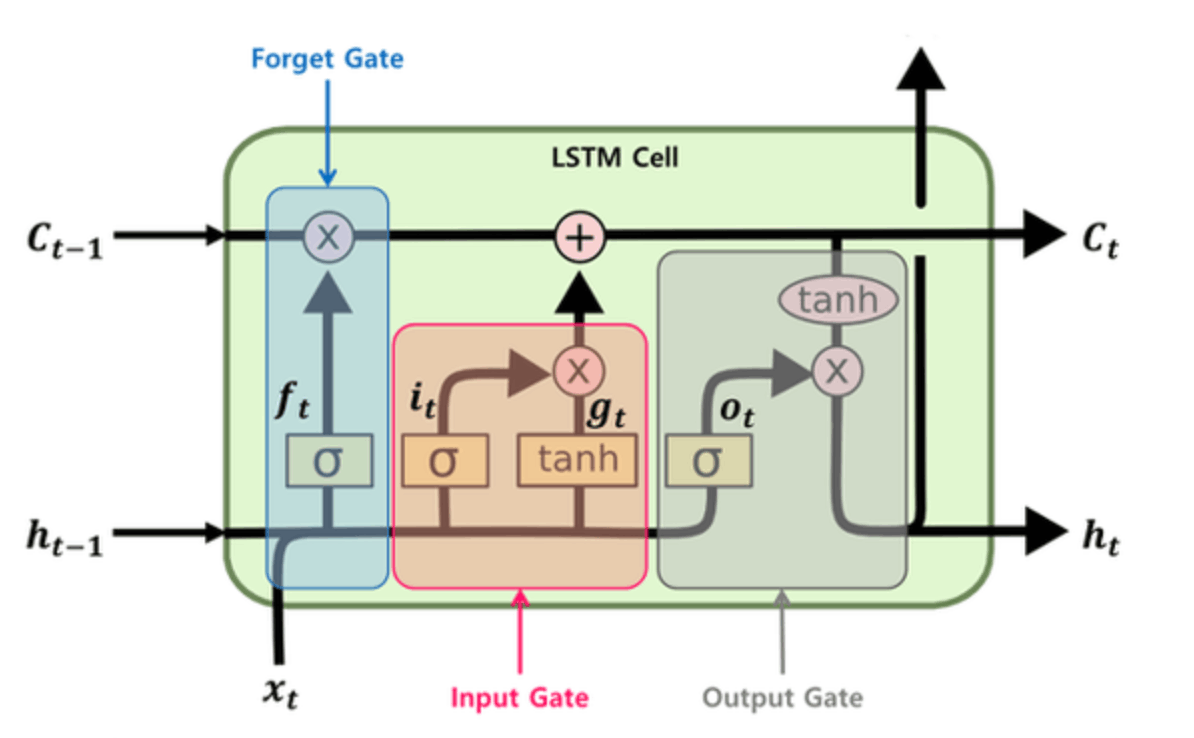
Cell State (c)
네트워크를 통해 직선적으로 흐르며, 정보를 장기간 보존하는 역할
Input Gate (i)
새롭게 들어온 정보를 기존 cell state에 얼마나 반영할지를 결정하는 gate (sigmoid)
Forget Gate (f)
cell state의 기존 정보를 얼마나 잊어버릴지를 결정하는 gate (sigmoid)
Output Gate (o)
새롭게 만들어진 cell state를 새로운 hidden state에 얼마나 반영할지를 결정하는 gate (sigmoid)
Candidate Gate (g)
셀의 상태에 추가할 수 있는 새로운 후보 값의 벡터를 생성하는 역할을 담당 (tanh)
코드
lstm_seq_layer = tf.keras.layers.LSTM(units=64, return_sequences=True, use_bias=False)
lstm_seq_out = lstm_seq_layer(emb_out)
print("\nLSTM 결과 (모든 Step Output):", lstm_seq_out.shape)
print("LSTM Layer의 Weight 형태:", lstm_seq_layer.weights[0].shape)
lstm_fin_layer = tf.keras.layers.LSTM(units=64, use_bias=False)
lstm_fin_out = lstm_fin_layer(emb_out)
print("\nLSTM 결과 (최종 Step Output):", lstm_fin_out.shape)
print("LSTM Layer의 Weight 형태:", lstm_fin_layer.weights[0].shape) # 100 * 256 출력 W_xh
print(lstm_fin_layer.weights[1].shape) # 64 * 256 출력 W_hhGRU (Gated Recurrent Unit)
GRU는 기존 LSTM을 보다 단순하게 만든 구조로, cell state와 hidden state를 합치고, forget gate와 input gate를 통합했습니다.(아래 그림의 $z_t$에 해당하며 update gate라고도 불립니다.)
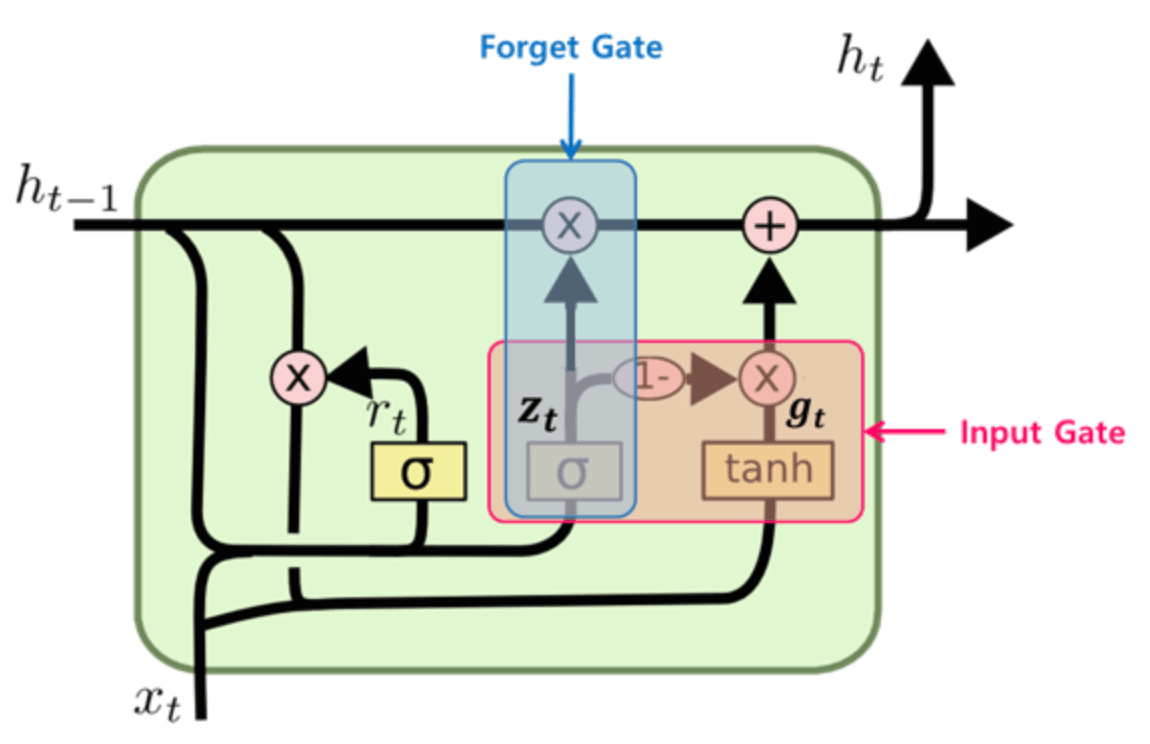
Reset Gate (r)
과거의 정보를 적당히 리셋시킴.(sigmoid) != forget gate
Update Gate (z)
LSTM의 forget gate와 input gate를 합쳐놓은 느낌으로 과거와 현재의 정보의 최신화 비율 결정 (sigmoid)
Candidate (g)
현시점의 정보 후보군을 계산하는 단계. 핵심은 과거 은닉층의 정보를 그대로 사용하지 않고 리셋게이트의 결과를 곱하여 이용 (tanh)
GRU의 LSTM 대비 장점
LSTM에 비해 GRU가 학습할 가중치(Weight)가 더 적다. (LSTM의 1/4 만큼)
적은 데이터에서도 성능을 보여주는 편.
양방향 RNN (Bidirectional RNN)
진행 방향이 반대인 RNN을 두개 겹쳐놓은 형태
사용하고자하는 레이어에
tf.keras.layers.Bidirectional()
로 감싸주기만 하면 됨.
문장 분석이나 생성보다는 주로 기계번역 같은 테스크에 유리합니다. 사람도 대화를 하면서 듣고 이해하는 것은 순차적으로 들으면서 충분히 예측을 동원해서 잘 해냅니다. 그러나 문장을 번역하려면 일단은 번역해야 할 문장 전체를 끝까지 분석한 후 번역을 시도하는 것이 훨씬 유리합니다. 그래서 자연어처리를 계속하면서 알게 되겠지만, 번역기를 만들 때 양방향(Bidirectional) RNN 계열의 네트워크, 혹은 동일한 효과를 내는 Transformer 네트워크를 주로 사용하게 될 것입니다.
임베딩 레이어는 깊을수록 좋을까요?
임베딩 레이어의 깊이가 깊을수록 항상 좋은 것은 아닙니다. 임베딩 레이어는 일반적으로 입력 데이터의 차원을 줄이는 역할을 하기 때문에, 데이터의 추상화 및 표현 능력을 향상시키는 데 도움을 줄 수 있습니다. 따라서, 적절한 깊이를 선택하는 것이 중요합니다.하지만 임베딩 레이어의 깊이가 지나치게 깊으면, 모델의 복잡도가 높아져 과적합(Overfitting)이 발생할 가능성이 있습니다. 또한, 임베딩 레이어가 깊을수록 계산 비용이 높아질 수 있습니다. 따라서, 깊이를 선택할 때는 모델의 복잡도와 계산 비용을 고려해야 합니다.또한, 임베딩 레이어의 깊이는 문제의 복잡도에 따라 달라질 수 있습니다. 간단한 문제에서는 얕은 임베딩 레이어가 충분할 수 있지만, 복잡한 문제에서는 깊은 임베딩 레이어가 필요할 수 있습니다. 따라서, 문제에 맞는 적절한 깊이를 선택하는 것이 중요합니다.
'AI > 인공지능 기초' 카테고리의 다른 글
| Deep Learning Layer: Convolution Layer (0) | 2023.11.20 |
|---|---|
| Deep Learning Layer: Linear Layer (1) | 2023.11.20 |
| 딥러닝 들여다보기 (0) | 2023.11.13 |
| MLP(Multi Layer Perceptron) 과정 (1) | 2023.11.13 |
| 전처리 기법: 원-핫 인코딩(One-Hot Encoding), 구간화(Data bining) (0) | 2023.11.12 |

