
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 딥러닝 실험 깃 버전관리
- 인공지능 깃 버전관리
- 영화 api
- 백준
- pandas
- 경사하강법
- 정규화
- 대학원 급여
- 디자인패턴
- 파이썬 경사하강법
- Dehaze
- 파이썬
- 통계학
- 의료 ai 대학원 월급
- 자바 프로젝트
- python
- 딥러닝
- MLP
- API
- 디자인 패턴
- 대학원 월급
- 코딩테스트
- 로스트아크
- 인공지능
- DCP
- 자바 영화 api
- 활성화 함수
- 머신러닝
- C# 프로젝트
- 자바
- Today
- Total
대학원 일기
[논문 리뷰] Pseudo-LiDAR from Visual Depth Estimation: Bridging the Gap in 3D Object Detection for Autonomous Driving 본문
[논문 리뷰] Pseudo-LiDAR from Visual Depth Estimation: Bridging the Gap in 3D Object Detection for Autonomous Driving
대학원생(노예) 2022. 1. 24. 09:30
이 논문을 읽게 된 계기는 세계적 기업인 테슬라의 기술력을 찾고 공부하는 과정에서 보게 되었다. 테슬라는 다른 기업들처럼 값비싼 라이다, 레이더에 의존하지 않고, 카메라를 이용하여 완전한 자율주행을 구현하는 것을 목표로 한다. 테슬라의 자율주행은 8개의 카메라, 초음파 센서 12개만 탑재하여 이루어지고 있다. 이를 통해 LiDAR를 사용하는 자율주행 자동차와 가격의 차이가 벌어지지만, LiDAR에 비해 성능이 좋지 않은 것은 사실이다. 하지만, 테슬라는 SW 기술을 통해 자율주행 능력을 개선하여 값비싼 LiDAR와 성능의 차이가 크게 나지 않는다.
본 논문은 테슬라의 자율주행 능력을 개선시킨 방법이다. 연구진은 카메라로 픽셀의 깊이를 측정하고, 그 깊이를 위상에 근거하여 3D 이미지를 추정하여 LiDAR와 같은 3차원 Map을 만드는데 성공하고, 이를 LiDAR와 같은 3D object detection 알고리즘을 적용하여 정확도를 크게 높였다. 아래의 링크를 통해 논문은 확인할 수 있다.
Pseudo-LiDAR from Visual Depth Estimation: Bridging the Gap in 3D Object Detection for Autonomous Driving
3D object detection is an essential task in autonomous driving. Recent techniques excel with highly accurate detection rates, provided the 3D input data is obtained from precise but expensive LiDAR technology. Approaches based on cheaper monocular or stere
arxiv.org
Abstract
LiDAR(Light Detection and Ranging) 기술은 자동차 자율주행의 핵심인 3D object detection에서 높은 정확도를 가지지만, 매우 고가라는 단점이 있다. 본 논문은 monocular 혹은 stereo image에서의 3D object detection이 낮은 정확도를 가지는 것을 보고 LiDAR 기술을 모방하여 이미지 기반의 depth map(깊이 지도)을 pseudo-LiDAR 기반으로 변환하여 3D object detection의 성능을 개선하였다.
1. Introduction
현재 자동차 자율주행의 핵심인 3D object detection 알고리즘은 LiDAR(Light Detection And Ranging) 기술에서 높은 정확도를 제공한다. 하지만, LiDAR 기술은 지나치게 비싼 가격과 하나의 장비에만 의존한다는 문제점 때문에 LiDAR 기술의 대안으로 다양한 방법들이 나오고 있다.

위의 그림 1(Figure 1)은 LiDAR로 생성된 3D point cloud 데이터와 이미지 기반의 stereo depth estimation으로 생성된 pseudo-LiDAR 데이터가 매우 유사하게 일치하는 것을 볼 수 있다.
이 논문은 입력 데이터의 3D depth 정보를 추정하여 depth map을 만들고 pseudo-LiDAR 데이터로 변환하여 이미지 기반의 3D object detection 알고리즘 성능을 개선시켰다. 이를 통해, 자율주행에서 monocular 또는 stereo 카메라를 사용하여 비용을 절감하고 안정성을 개선시킬 수 있다고 한다.
2. Related Work
LiDAR based 3D object detection
이 논문은 최근의 3D Vision과 LiDAR를 기반으로 한 3D object detection으로 고안되었다. 최신 기술들은 3D point clouds로 표현된 LiDAR를 사용한다. 그 예는 다음과 같다.
frustum PointNet
frustum PointNet 알고리즘은 PointNet에 2D object detection network로부터 각각의 frustum proposal를 적용한다.
MV3D
MV3D는 LiDAR 데이터를 bird-eye view(BEV, Fig1)와 fronal view로 사영시켜 다시점의 특징을 추출하여 얻는다.
VoxelNet
VoxelNet은 3D 포인트를 복셀로 인코딩하고 3D convoltions을 통해 특징을 추출한다.
이러한 알고리즘들은 정확한 3D point 좌표를 가진다고 가정하기 때문에 주요 과제는 point label를 추정하거나 3D 좌표에서 object의 위치를 추정하기 위해 3D bouding box를 그려야 한다.
Stereo and monocular based depth estimation
이미지 기반의 3D object detection 알고리즘의 핵심은 LiDAR를 대체할 수 있는 depth estimation이다. 이러한 이미지들을 monocular 혹은 stero vison을 통해 알고리즘의 정확도는 급격하게 향상되었고, 이로 이미지 깊이 추정으로 이미지 기반의 3D object detection을 해결할 수 있게 되었다.
Image based 3D object detection
stereo 와 monocular를 통한 빠른 depth estimation으로 이미지 기반의 3D object detection을 LiDAR를 대체할 수 있게 되었다. 기존 알고리즘들은 2D object detection에 추가적으로 기하학적인 제약조건을 걸어 3D 정보를 생성했었다. 추가적으로, stereo pixel을 적용한 알고리즘은 depth estimation을 통해 실제 3D 좌표를 구했다. 하지만, 이러한 방법들도 LiDAR의 성능보다 좋지 않은 것을 확인할 수 있었고, 그 원인으로는 depth representation(깊이 데이터의 표현)이 문제라고 예측했다.
3. Approach
이미지 기반의 3D object detection과 LiDAR를 기반으로 한 접근에는 큰 차이가 있다. 우선, stereo 기반의 depth estimation error는 물체의 depth에 따라 quardratic(2차적으로?)하게 증가하지만, LiDAR와 같은 Time-of-Flight(TOF) 기반의 depth estimation은 대략 linear(선형적)으로 증가한다. 이렇게 물리적인 차이로 정확도가 차이가 생길 수 있지만, 이와 달리 본 논문의 저자들은 이미지 기반의 3D object detection에서 depth 데이터의 representation(표현 방식)이 가장 큰 원인이라고 주장한다.
저자들은 LiDAR 알고리즘과의 "close the gap"을 위해 두 데이터 modalities 간의 차이를 제거하고, 두 recognition pipelines를 최대한 정렬해야 한다고 한다. 이를 위해, stereo 또는 monocular 이미지에서 픽셀 dense(밀도)를 추정하고 이를 back-propagation하여 3D point cloud로 변환한다. 즉, 데이터 표현방식을 pixel depth에서 3D point cloud로 바꿔 LiDAR 알고리즘을 모방하여 사용할 수 있게 된다. 저자들은 이를 pseudo-LiDAR 라고 표현했다.
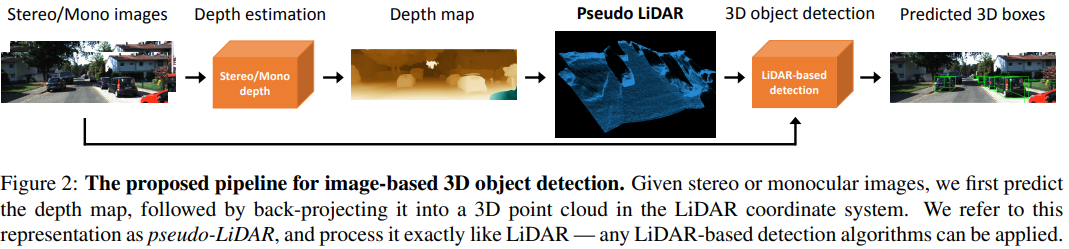
Depth estimation
$D(u, v) = \frac{f_{U} \times b}{Y (u, v)}$
위 식은 stereo 이미지를 Depth estimation(stereo disparity estimation algorithm)으로 구하는 depth map D이다.
(monocular로도 가능)
- $b$ : horizontal offset(baseline)
- $Y$ : same size as either one of the two input images
- $f_{U}$: horizontal focal length
stereo disparity estimation 알고리즘은 horizontal offset($b$)가 있는 카메라 쌍에서 캡처된 왼쪽-오른쪽 이미지 쌍 $I_{l}$와 $I_{r}$를 입력으로 가져가고 두 입력 이미지 중 하나와 동일한 크기의 차이 맵 $Y$를 출력한다. 일반적으로 loss 없이 depth estimation 알고리즘은 왼쪽 이미지 $I_{l}$ 을 참조로 처리하고 $Y$에서 각 픽셀에 대한 $I_{r}$에 대한 horizontal disparity를 기록한다고 가정하면 왼쪽 카메라의 horizontal focal length(수평 초점 거리) $f_{U}$와 함께, depth map $D$를 도출할 수 있다.
Pseudo-LiDAR generation
각각의 pixel $(u, v)$ 에 대한 3D 좌표 $(x,y, z)$ 값은 다음과 같이 구한다.

- $(c_{U} , c_{V})$ : 카메라 중심에 해당하는 픽셀 위치
- $f_{V}$ : 수직 초점 거리
- $N$ : 픽셀 수
이 방식으로 depth-map에 포함된 모든 픽셀에 대한 3D 좌표정보$(x,y,z)$를 추출하여 3D point cloud 데이터를 복원할 수 있습니다.
Such a point cloud can be transformed into any cyclopean coordinate frame given a reference viewpoint and viewing direction. We refer to the resulting point cloud as pseudo-LiDAR signal.
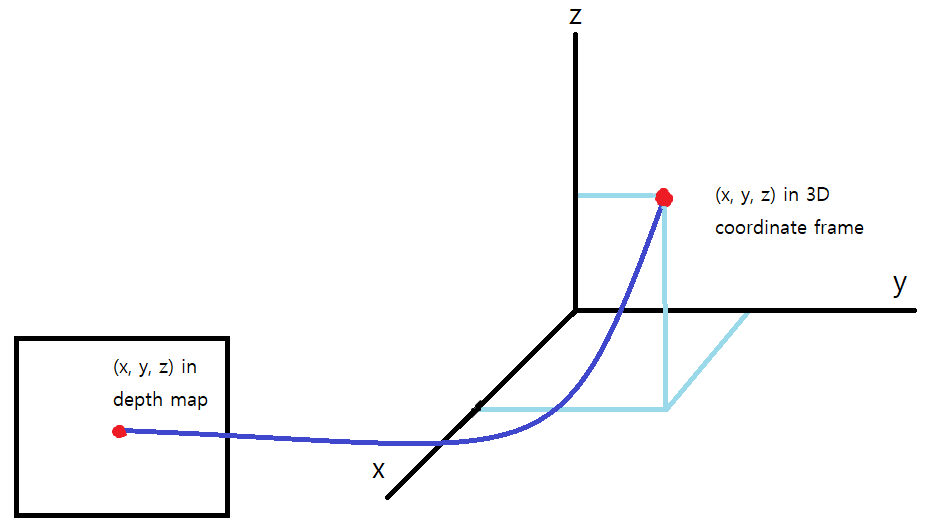
위 그래프를 통해 point cloud를 얻고, 논문의 저자들은 이를 pseudo-LiDAR 신호라고 부른다.
LiDAR vs pseudo-LiDAR
실제 LiDAR 신호는 특정 높이 범위에만 존재한다. Pseudo-LiDAR는 LiDAR와 동일하게 가기 위해서 그 특정 범위를 초과하는 pseudo-LiDAR point는 무시한다.
Depth estimation은 pyramid stereo matching network(PSMNet)을 통해 얻는다. 다음 그림에서 pseudo-LiDAR points(blue)는 실제 LiDAR points(yellow)에 상당히 잘 근접해 있음을 확인 할 수 있습니다.

3D object detection
추정된 pseudo-LiDAR points 를 사용하여 기존의 LiDAR-based 3D object detector를 적용할 수 있게 되었다.
이 과정에서 multimodal 정보(monocular images + LiDAR)에 고려했다. 3D object detection을 수행하기 위하여
1) Aggregate View Object Detection(AVOD)
2) frustum PointNet
위 두 가지 방식을 선택하여 연구를 했다.
Aggregate View Object Detection(AVOD)
AVOD는 pseudo-LiDAR 정보를 3D point cloud로 취급한다. 여기서 2D Object detection를 3D frustum에 projection(투영)한 다음 PointNet을 적용하여 각 3D frustum에서 point-set 특징을 추출한다.
frustum PointNet
frustum PointNet은 BEV(Bird's Eye View)에서 pseudo-LiDAR 정보를 본다. 3D 정보는 top→down(하향식) view에서 2D 영상으로 변환되었고, Width와 Depth정보는 spatial dimension으로 변환되고, height 정보는 색상의 채널 공간으로 변환된다. AVOD는 visual 특징과 BEV LiDAR 특징을 결합하여 regeression과 classification을 수행한다.
Data representation matters
논문의 저자들은 pseudo-LiDAR 데이터는 depth map 정보를 포함하고 있지만 이러한 형태의 데이터는 3D object detection에 더 적합하다고 주장한다.
2D convolution을 2D 영상이나 depth-map에 적용할 때 두가지 가정이 필요하다. 첫째는 영상의 local neighborhoods 가 의미있어야 하고, 둘째는 각 픽셀의 local neighborhood가 동일한 방식으로 처리되어야 한다. 이 두가지 가정이 충족되지 않은 경우에 대한 예로 depth-map에서 인접한 두 픽셀 영역이 실제 물리적 거리에서는 매우 먼 거리에 존재하는 경우와 하나의 object가 여러 스케일의 depth-map의 부분으로 표현되는 경우가 있다. 현재 존재하는 2D object detection 알고리즘들은 이러한 조건에서 잘 적용이 안된다고 한다.
이와 반대로 point cloud 데이터(3D points)에 3D convolution을 적용하거나 birds’s-eye view slices(BEV, 2D points)의 pixel에 2D convolution를 적용하는 경우, 실제 물리적으로 픽셀 영역이 가까운 부분이 된다. 따라서 이러한 경우의 operation들은 실제 물리적으로 의미가 있고 학습이 더 잘 되거나 정확한 모델을 구성할 수 있다. 다음 사진은 depth-map에 직접 2d convolution 을 적용한 것이다.

그림의 왼쪽 칼럼에서 original depth-map 과 pseudo-LiDAR 데이터를 확인할 수 있다. 자동차들은 특정 색상으로 표시된다. 11x11 convolution을 depth-map에 적용한 후(그림 3의 오른쪽 위 그림) 다시 새로운 pseudo-LiDAR 데이터로 표현하면 실제 depth-map의 blurring 된 영역에서 부정확한 데이터 결과가 나오는 것을 확인 할 수 있다. 이 실험을 통해 depth-map에 2D convolution 적용보다는 그것의 3D 좌표 transform을 통한 pseudo-LiDAR 데이터(bird`s eye view slices) 의 2D convolution 적용이 효과적임을 알 수 있다.
Result Image



Experiments
Table 1

Table 2

Table 3

Table 4

Table 5




